降载
为什么需要降载
微服务集群中,调用链路错综复杂,作为服务提供者需要有一种保护自己的机制,防止调用方无脑调用压垮自己,保证自身服务的高可用。
最常见的保护机制莫过于限流机制,使用限流器的前提是必须知道自身的能够处理的最大并发数,一般在上线前通过压测来得到最大并发数,而且日常请求过程中每个接口的限流参数都不一样,同时系统一直在不断的迭代其处理能力往往也会随之变化,每次上线前都需要进行压测然后调整限流参数变得非常繁琐。
那么有没有一种更加简洁的限流机制能实现最大限度的自我保护呢?
什么是自适应降载
自适应降载能非常智能的保护服务自身,根据服务自身的系统负载动态判断是否需要降载。
设计目标:
- 保证系统不被拖垮。
- 在系统稳定的前提下,保持系统的吞吐量。
那么关键就在于如何衡量服务自身的负载呢?
判断高负载主要取决于两个指标:
- cpu 是否过载。
- 最大并发数是否过载。
以上两点同时满足时则说明服务处于高负载状态,则进行自适应降载。
同时也应该注意高并发场景 cpu 负载、并发数往往波动比较大,从数据上我们称这种现象为毛刺,毛刺现象可能会导致系统一直在频繁的进行自动降载操作,所以我们一般获取一段时间内的指标均值来使指标更加平滑。实现上可以采用准确的记录一段时间内的指标然后直接计算平均值,但是需要占用一定的系统资源。
统计学上有一种算法:滑动平均(exponential moving average),可以用来估算变量的局部均值,使得变量的更新与历史一段时间的历史取值有关,无需记录所有的历史局部变量就可以实现平均值估算,非常节省宝贵的服务器资源。
滑动平均算法原理 参考这篇文章讲的非常清楚。
变量 V 在 t 时刻记为 Vt,θt 为变量 V 在 t 时刻的取值,即在不使用滑动平均模型时 Vt=θt,在使用滑动平均模型后,Vt 的更新公式如下:
Vt=β⋅Vt−1+(1−β)⋅θt
- β = 0 时 Vt = θt
- β = 0.9 时,大致相当于过去 10 个 θt 值的平均
- β = 0.99 时,大致相当于过去 100 个 θt 值的平均
代码实现
接下来我们来看下 go-zero 自适应降载的代码实现。
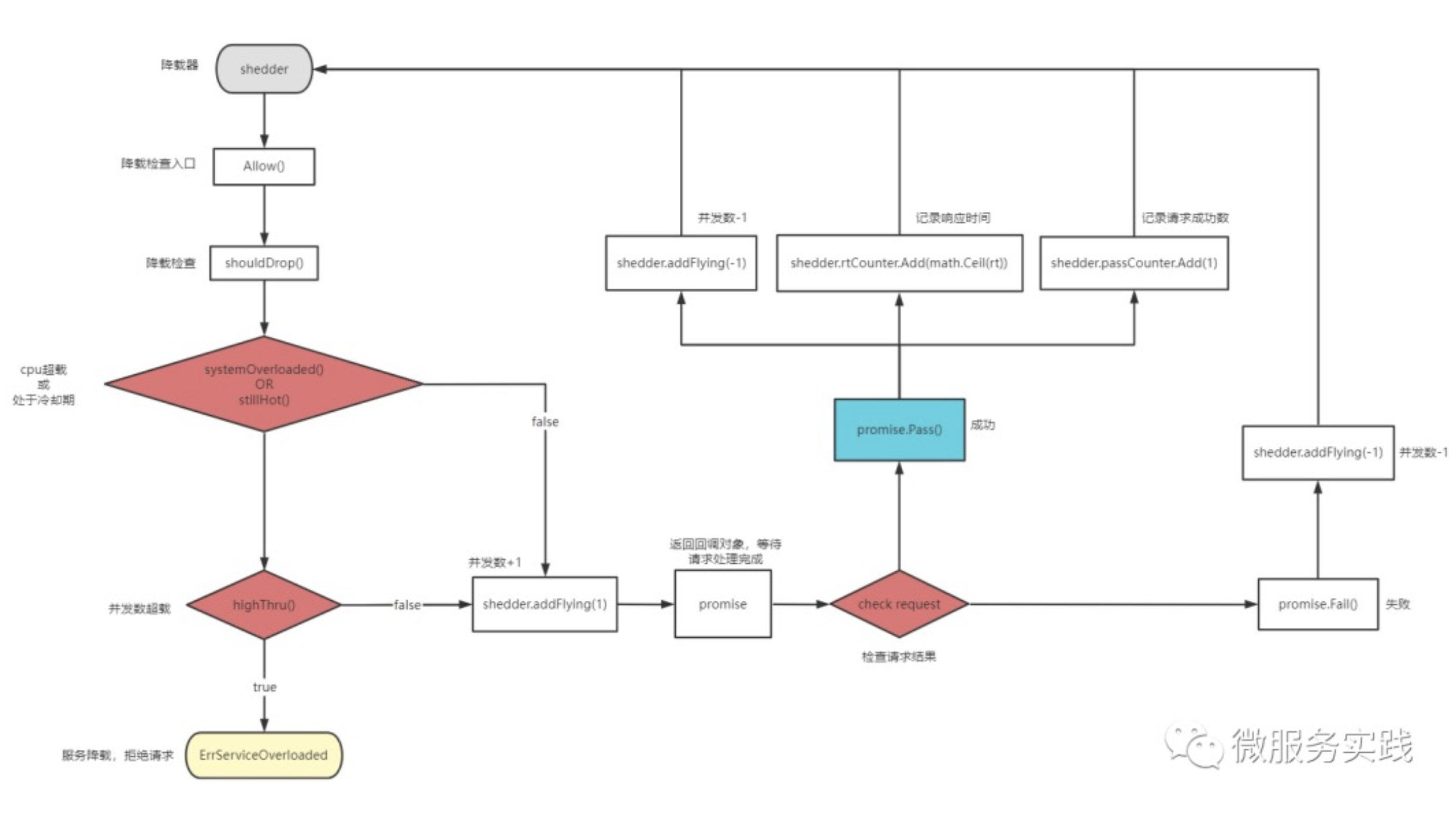
自适应降载接口定义:
// 回调函数
Promise interface {
// 请求成功时回调此函数
Pass()
// 请求失败时回调此函数
Fail()
}
// 降载接口定义
Shedder interface {
// 降载检查
// 1. 允许调用,需手动执行 Promise.accept()/reject()上报实际执行任务结构
// 2. 拒绝调用,将会直接返回err:服务过载错误 ErrServiceOverloaded
Allow() (Promise, error)
}
接口定义非常精简意味使用起来其实非常简单,对外暴露一个`Allow()(Promise,error)。
go-zero 使用示例:
业务中只需调该方法判断是否降载,如果被降载则直接结束流程,否则执行业务最后使用返回值 Promise 根据执行结果回调结果即可。
func UnarySheddingInterceptor(shedder load.Shedder, metrics *stat.Metrics) grpc.UnaryServerInterceptor {
ensureSheddingStat()
return func(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo,
handler grpc.UnaryHandler) (val interface{}, err error) {
sheddingStat.IncrementTotal()
var promise load.Promise
// 检查是否被降载
promise, err = shedder.Allow()
// 降载,记录相关日志与指标
if err != nil {
metrics.AddDrop()
sheddingStat.IncrementDrop()
return
}
// 最后回调执行结果
defer func() {
// 执行失败
if err == context.DeadlineExceeded {
promise.Fail()
// 执行成功
} else {
sheddingStat.IncrementPass()
promise.Pass()
}
}()
// 执行业务方法
return handler(ctx, req)
}
}
接口实现类定义 :
主要包含三类属性
- cpu 负载阈值:超过此值意味着 cpu 处于高负载状态。
- 冷却期:假如服务之前被降载过,那么将进入冷却期,目的在于防止降载过程中负载还未降下来立马加压导致来回抖动。因为降低负载需要一定的时间,处于冷却期内应该继续检查并发数是否超过限制,超过限制则继续丢弃请求。
- 并发数:当前正在处理的并发数,当前正在处理的并发平均数,以及最近一段内的请求数与响应时间,目的是为了计算当前正在处理的并发数是否大于系统可承载的最大并发数。
// option参数模式
ShedderOption func(opts *shedderOptions)
// 可选配置参数
shedderOptions struct {
// 滑动时间窗口大小
window time.Duration
// 滑动时间窗口数量
buckets int
// cpu负载临界值
cpuThreshold int64
}
// 自适应降载结构体,需实现 Shedder 接口
adaptiveShedder struct {
// cpu负载临界值
// 高于临界值代表高负载需要降载保证服务
cpuThreshold int64
// 1s内有多少个桶
windows int64
// 并发数
flying int64
// 滑动平滑并发数
avgFlying float64
// 自旋锁,一个服务共用一个降载
// 统计当前正在处理的请求数时必须加锁
// 无损并发,提高性能
avgFlyingLock syncx.SpinLock
// 最后一次拒绝时间
dropTime *syncx.AtomicDuration
// 最近是否被拒绝过
droppedRecently *syncx.AtomicBool
// 请求数统计,通过滑动时间窗口记录最近一段时间内指标
passCounter *collection.RollingWindow
// 响应时间统计,通过滑动时间窗口记录最近一段时间内指标
rtCounter *collection.RollingWindow
}
自适应降载构造器:
func NewAdaptiveShedder(opts ...ShedderOption) Shedder {
// 为了保证代码统一
// 当开发者关闭时返回默认的空实现,实现代码统一
// go-zero很多地方都采用了这种设计,比如Breaker,日志组件
if !enabled.True() {
return newNopShedder()
}
// options模式设置可选配置参数
options := shedderOptions{
// 默认统计最近5s内数据
window: defaultWindow,
// 默认桶数量50个
buckets: defaultBuckets,
// cpu负载
cpuThreshold: defaultCpuThreshold,
}
for _, opt := range opts {
opt(&options)
}
// 计算每个窗口间隔时间,默认为100ms
bucketDuration := options.window / time.Duration(options.buckets)
return &adaptiveShedder{
// cpu负载
cpuThreshold: options.cpuThreshold,
// 1s的时间内包含多少个滑动窗口单元
windows: int64(time.Second / bucketDuration),
// 最近一次拒绝时间
dropTime: syncx.NewAtomicDuration(),
// 最近是否被拒绝过
droppedRecently: syncx.NewAtomicBool(),
// qps统计,滑动时间窗口
// 忽略当前正在写入窗口(桶),时间周期不完整可能导致数据异常
passCounter: collection.NewRollingWindow(options.buckets, bucketDuration,
collection.IgnoreCurrentBucket()),
// 响应时间统计,滑动时间窗口
// 忽略当前正在写入窗口(桶),时间周期不完整可能导致数据异常
rtCounter: collection.NewRollingWindow(options.buckets, bucketDuration,
collection.IgnoreCurrentBucket()),
}
}
降载检查 Allow():
检查当前请求是否应该被丢弃,被丢弃业务侧需要直接中断请求保护服务,也意味着降载生效同时进入冷却期。如果放行则返回 promise,等待业务侧执行回调函数执行指标统计。
// 降载检查
func (as *adaptiveShedder) Allow() (Promise, error) {
// 检查请求是否被丢弃
if as.shouldDrop() {
// 设置drop时间
as.dropTime.Set(timex.Now())
// 最近已被drop
as.droppedRecently.Set(true)
// 返回过载
return nil, ErrServiceOverloaded
}
// 正在处理请求数加1
as.addFlying(1)
// 这里每个允许的请求都会返回一个新的promise对象
// promise内部持有了降载指针对象
return &promise{
start: timex.Now(),
shedder: as,
}, nil
}
检查是否应该被丢弃shouldDrop():
// 请求是否应该被丢弃
func (as *adaptiveShedder) shouldDrop() bool {
// 当前cpu负载超过阈值
// 服务处于冷却期内应该继续检查负载并尝试丢弃请求
if as.systemOverloaded() || as.stillHot() {
// 检查正在处理的并发是否超出当前可承载的最大并发数
// 超出则丢弃请求
if as.highThru() {
flying := atomic.LoadInt64(&as.flying)
as.avgFlyingLock.Lock()
avgFlying := as.avgFlying
as.avgFlyingLock.Unlock()
msg := fmt.Sprintf(
"dropreq, cpu: %d, maxPass: %d, minRt: %.2f, hot: %t, flying: %d, avgFlying: %.2f",
stat.CpuUsage(), as.maxPass(), as.minRt(), as.stillHot(), flying, avgFlying)
logx.Error(msg)
stat.Report(msg)
return true
}
}
return false
}
cpu 阈值检查 systemOverloaded():
cpu 负载值计算算法采用的滑动平均算法,防止毛刺现象。每隔 250ms 采样一次 β 为 0.95,大概相当于历史 20 次 cpu 负载的平均值,时间周期约为 5s。
// cpu 是否过载
func (as *adaptiveShedder) systemOverloaded() bool {
return systemOverloadChecker(as.cpuThreshold)
}
// cpu 检查函数
systemOverloadChecker = func(cpuThreshold int64) bool {
return stat.CpuUsage() >= cpuThreshold
}
// cpu滑动平均值
curUsage := internal.RefreshCpu()
prevUsage := atomic.LoadInt64(&cpuUsage)
// cpu = cpuᵗ⁻¹ * beta + cpuᵗ * (1 - beta)
// 滑动平均算法
usage := int64(float64(prevUsage)*beta + float64(curUsage)*(1-beta))
atomic.StoreInt64(&cpuUsage, usage)
检查是否处于冷却期 stillHot:
判断当前系统是否处于冷却期,如果处于冷却期内,应该继续尝试检查是否丢弃请求。主要是防止系统在过载恢复过程中负载还未降下来,立马又增加压力导致来回抖动,此时应该尝试继续丢弃请求。
func (as *adaptiveShedder) stillHot() bool {
// 最近没有丢弃请求
// 说明服务正常
if !as.droppedRecently.True() {
return false
}
// 不在冷却期
dropTime := as.dropTime.Load()
if dropTime == 0 {
return false
}
// 冷却时间默认为1s
hot := timex.Since(dropTime) < coolOffDuration
// 不在冷却期,正常处理请求中
if !hot {
// 重置drop记录
as.droppedRecently.Set(false)
}
return hot
}
检查当前正在处理的并发数highThru():
一旦 当前处理的并发数 > 并发数承载上限 则进入降载状态。
这里为什么要加锁呢?因为自适应降载时全局在使用的,为了保证并发数平均值正确性。
为什么这里要加自旋锁呢?因为并发处理过程中,可以不阻塞其他的 goroutine 执行任务,采用无锁并发提高性能。
func (as *adaptiveShedder) highThru() bool {
// 加锁
as.avgFlyingLock.Lock()
// 获取滑动平均值
// 每次请求结束后更新
avgFlying := as.avgFlying
// 解锁
as.avgFlyingLock.Unlock()
// 系统此时最大并发数
maxFlight := as.maxFlight()
// 正在处理的并发数和平均并发数是否大于系统的最大并发数
return int64(avgFlying) > maxFlight && atomic.LoadInt64(&as.flying) > maxFlight
}
如何得到正在处理的并发数与平均并发数呢?
当前正在的处理并发数统计其实非常简单,每次允许请求时并发数 +1,请求完成后 通过 promise 对象回调-1 即可,并利用滑动平均算法求解平均并发数即可。
type promise struct {
// 请求开始时间
// 统计请求处理耗时
start time.Duration
shedder *adaptiveShedder
}
func (p *promise) Fail() {
// 请求结束,当前正在处理请求数-1
p.shedder.addFlying(-1)
}
func (p *promise) Pass() {
// 响应时间,单位毫秒
rt := float64(timex.Since(p.start)) / float64(time.Millisecond)
// 请求结束,当前正在处理请求数-1
p.shedder.addFlying(-1)
p.shedder.rtCounter.Add(math.Ceil(rt))
p.shedder.passCounter.Add(1)
}
func (as *adaptiveShedder) addFlying(delta int64) {
flying := atomic.AddInt64(&as.flying, delta)
// 请求结束后,统计当前正在处理的请求并发
if delta < 0 {
as.avgFlyingLock.Lock()
// 估算当前服务近一段时间内的平均请求数
as.avgFlying = as.avgFlying*flyingBeta + float64(flying)*(1-flyingBeta)
as.avgFlyingLock.Unlock()
}
}
得到了当前的系统数还不够 ,我们还需要知道当前系统能够处理并发数的上限,即最大并发数。
请求通过数与响应时间都是通过滑动窗口来实现的,关于滑动窗口的实现可以参考 自适应熔断器那篇文章。
当前系统的最大并发数 = 窗口单位时间内的最大通过数量 * 窗口单位时间内的最小响应时间。
// 计算每秒系统的最大并发数
// 最大并发数 = 最大请求数(qps)* 最小响应时间(rt)
func (as *adaptiveShedder) maxFlight() int64 {
// windows = buckets per second
// maxQPS = maxPASS * windows
// minRT = min average response time in milliseconds
// maxQPS * minRT / milliseconds_per_second
// as.maxPass()*as.windows - 每个桶最大的qps * 1s内包含桶的数量
// as.minRt()/1e3 - 窗口所有桶中最小的平均响应时间 / 1000ms这里是为了转换成秒
return int64(math.Max(1, float64(as.maxPass()*as.windows)*(as.minRt()/1e3)))
}
// 滑动时间窗口内有多个桶
// 找到请求数最多的那个
// 每个桶占用的时间为 internal ms
// qps指的是1s内的请求数,qps: maxPass * time.Second/internal
func (as *adaptiveShedder) maxPass() int64 {
var result float64 = 1
// 当前时间窗口内请求数最多的桶
as.passCounter.Reduce(func(b *collection.Bucket) {
if b.Sum > result {
result = b.Sum
}
})
return int64(result)
}
// 滑动时间窗口内有多个桶
// 计算最小的平均响应时间
// 因为需要计算近一段时间内系统能够处理的最大并发数
func (as *adaptiveShedder) minRt() float64 {
// 默认为1000ms
result := defaultMinRt
as.rtCounter.Reduce(func(b *collection.Bucket) {
if b.Count <= 0 {
return
}
// 请求平均响应时间
avg := math.Round(b.Sum / float64(b.Count))
if avg < result {
result = avg
}
})
return result
}