缓存
前言
大家可以想一想:我们在流量激增的情况下,服务端哪个部分最有可能会是第一个瓶颈?我相信大部分人遇到的都会是数据库首先扛不住,量一起来,数据库慢查询,甚至卡死。此时,上层服务有怎么强的治理能力都是无济于事的。
所以我们常说看一个系统架构设计的好不好,很多时候看看缓存设计的如何就知道了。我们曾经遇到过这样的问题,在我加入之前,我们的服务是没有缓存的,虽然当时流量还不算高,但是每天到流量高峰时间段,大家就会特别紧张,一周宕机好几回,数据库直接被打死,然后啥也干不了,只能重启;我当时还是顾问,看了看系统设计,只能救急,就让大家先加上了缓存,但是由于大家对缓存的认知不够以及老系统的混乱,每个业务开发人员都会按照自己的方式来手撕缓存。这样导致的问题就是缓存用了,但是数据七零八落,压根没有办法保证数据的一致性。这确实是一个比较痛苦的经历,应该能引起大家的共鸣和回忆。
然后我把整个系统推倒重新设计了,其中缓存部分的架构设计在其中作用非常明显,于是有了今天的分享。
我主要分为以下几个部分跟大家探讨:
- 缓存系统常见问题
- 单行查询的缓存与自动管理
- 多行查询缓存机制
- 分布式缓存系统设计
- 缓存代码自动化实践
缓存系统涉及的问题和知识点是比较多的,我分为以下几个方面来讨论:
- 稳定性
- 正确性
- 可观测性
- 规范落地和工具建设
缓存系统稳定性
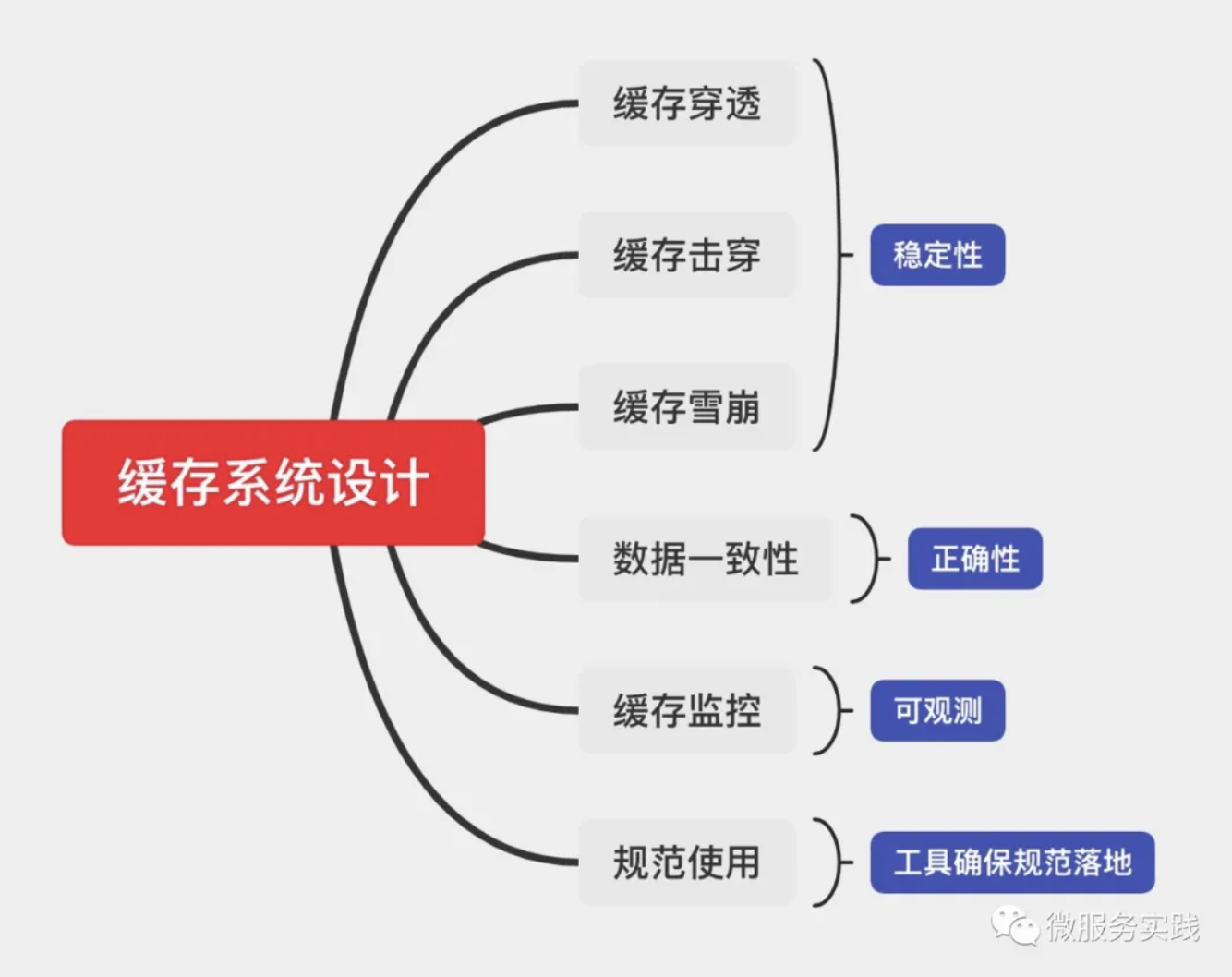
缓存稳定性方面,网上基本所有的缓存相关文章和分享都会讲到三个重点:
- 缓存穿透
- 缓存击穿
- 缓存雪崩
为什么首先讲缓存稳定性呢?大家可以回忆一下,我们何时会引入缓存?一般都是当DB有压力,甚至经常被打挂的情况下才会引入缓存,所以我们首先就是为了解决稳定性的问题而引入缓存系统的。
缓存穿透
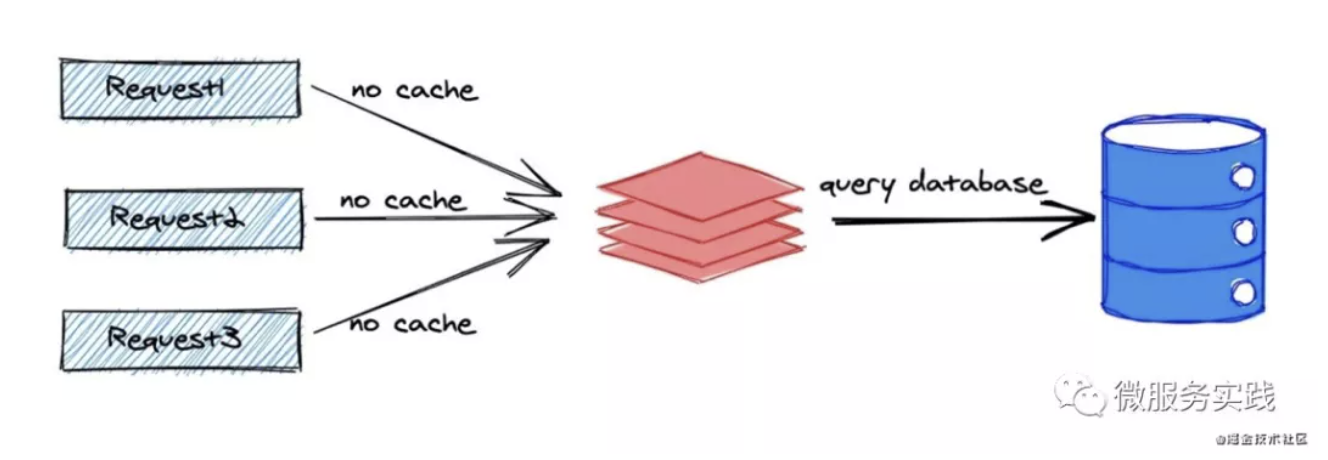
缓存穿透存在的原因是请求不存在的数据,从图中我们可以看到对同一个数据的请求1会先去访问缓存,但是因为数据不存在,所以缓存里肯定没有,那么就落到DB去了,对同一个数据的请求2、请求3也同样会透过缓存落到DB去,这样当大量请求不存在的数据时DB压力就会特别大,尤其是可能会恶意请求打垮(不怀好意的人发现一个数据不存在,然后就大量发起对这个不存在数据的请求)。
go-zero 的解决方法是:对于不存在的数据的请求我们也会在缓存里短暂(比如一分钟)存放一个占位符,这样对同一个不存在数据的DB请求数就会跟实际请求数解耦了,当然在业务侧也可以在新增数据时删除该占位符以确保新增数据可以立刻查询到。
缓存击穿
缓存击穿的原因是热点数据的过期,因为是热点数据,所以一旦过期可能就会有大量对该热点数据的请求同时过来,这时如果所有请求在缓存里都找不到数据,如果同时落到DB去的话,那么DB就会瞬间承受巨大的压力,甚至直接卡死。
go-zero 的解决方法是:对于相同的数据我们可以借助于 core/syncx/SharedCalls 来确保同一时间只有一个请求落到DB,对同一个数据的其它请求等待第一个请求返回并共享结果或错误,根据不同的并发场景,我们可以选择使用进程内的锁(并发量不是非常高),或者分布式锁(并发量很高)。如果不是特别需要,我们一般推荐进程内的锁即可,毕竟引入分布式锁会增加复杂度和成本,借鉴奥卡姆剃刀理论:如非必要,勿增实体。
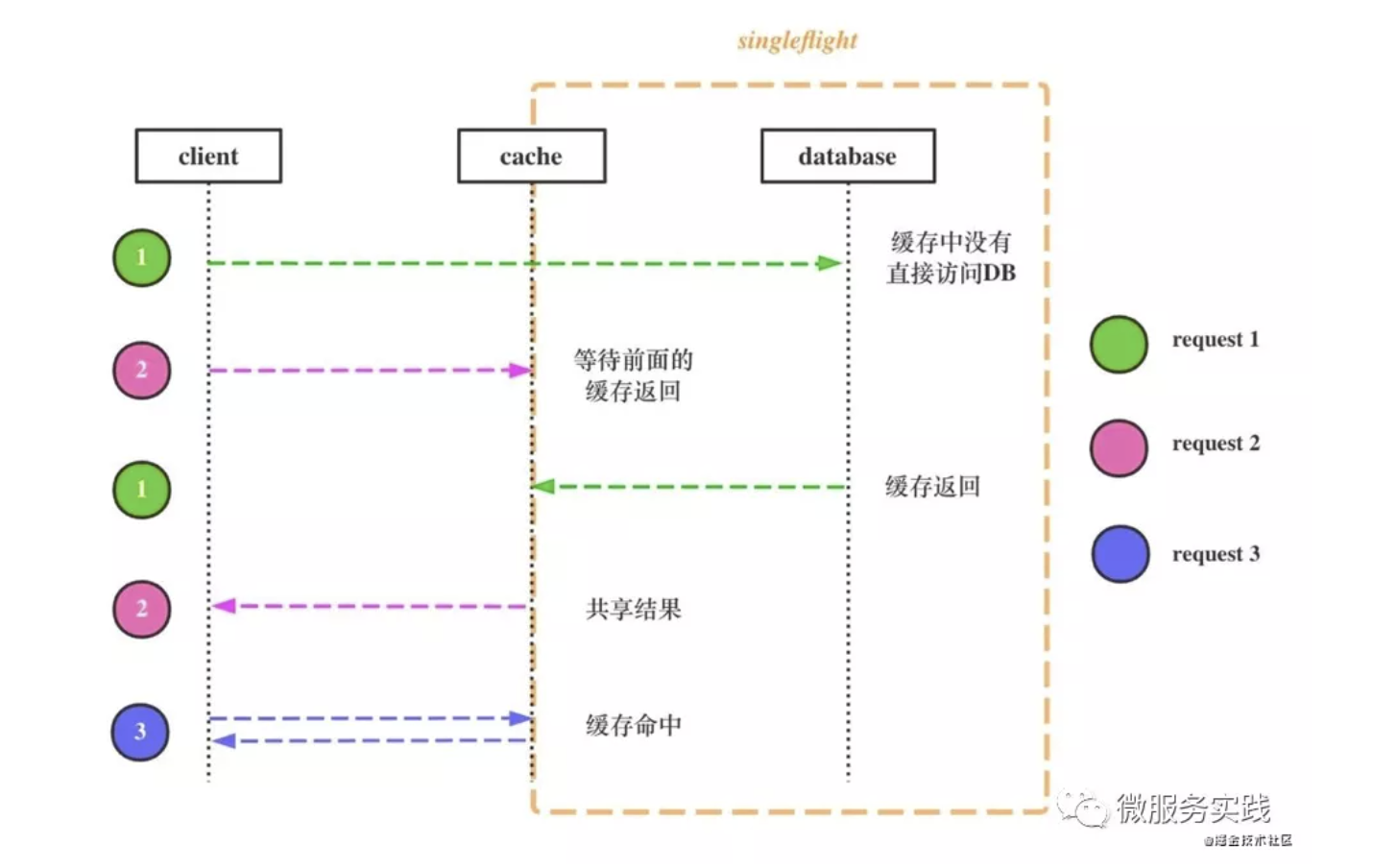
我们来一起看一下上图缓存击穿防护流程,我们用不同颜色表示不同请求:
- 绿色请求首先到达,发现缓存里没有数据,就去DB查询
- 粉色请求到达,请求相同数据,发现已有请求在处理中,等待绿色请求返回,singleflight模式
- 绿色请求返回,粉色请求用绿色请求共享的结果返回
- 后续请求,比如蓝色请求就可以直接从缓存里获取数据了
缓存雪崩
缓存雪崩的原因是大量同时加载的缓存有相同的过期时间,在过期时间到达的时候出现短时间内大量缓存过期,这样就会让很多请求同时落到DB去,从而使DB压力激增,甚至卡死。
比如疫情下在线教学场景,高中、初中、小学是分几个时间段同时开课的,那么这时就会有大量数据同时加载,并且设置了相同的过期时间,在过期时间到达的时候就会对等出现一个一个的DB请求波峰,这样的压力波峰会传递到下一个周期,甚至出现叠加。
go-zero 的解决方法是:
- 使用分布式缓存,防止单点故障导致的缓存雪崩
- 在过期时间上加上5%的标准偏差,5%是假设检验里P值的经验值(有兴趣的读者可以自行查阅)
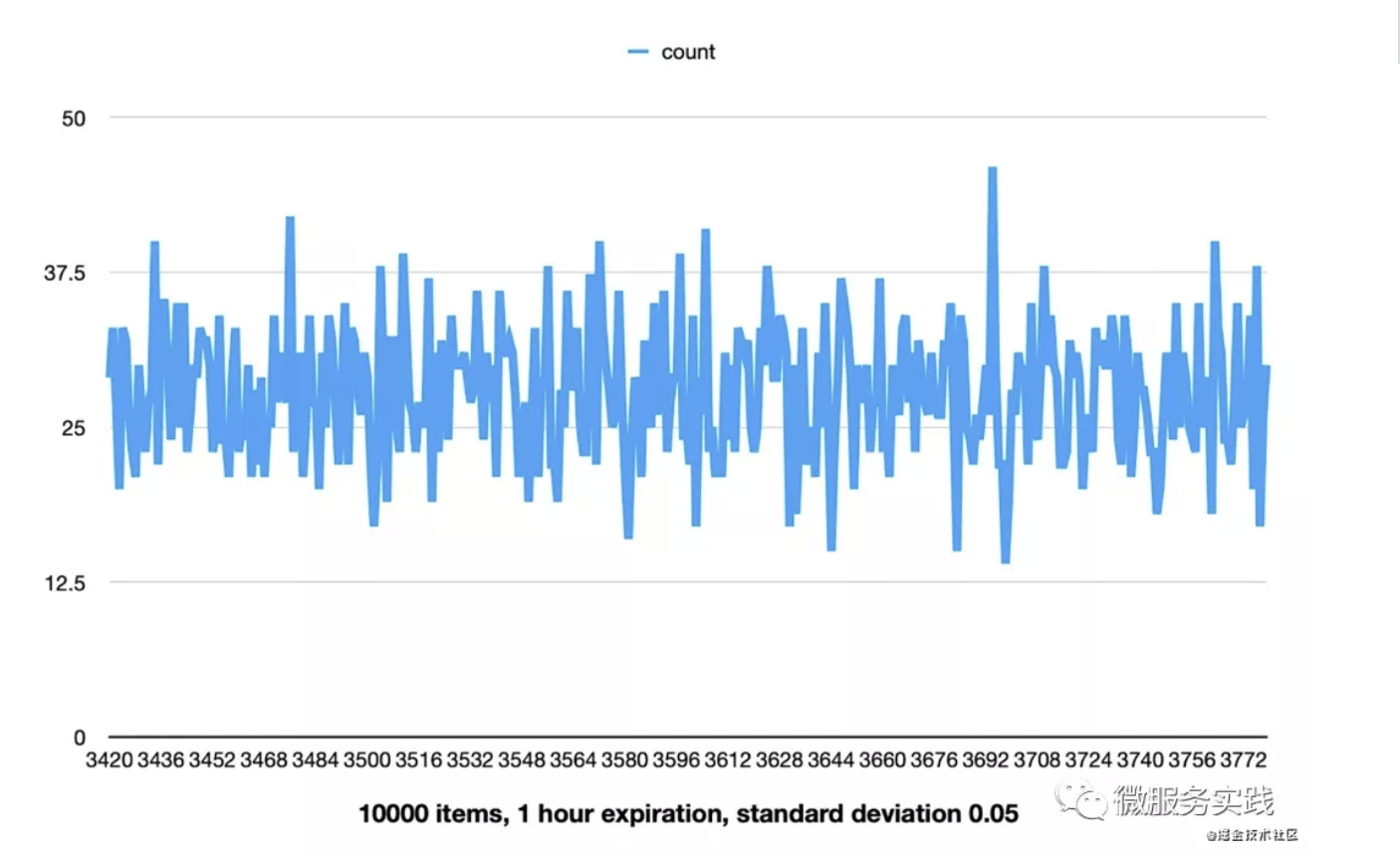
我们做个实验,如果用1万个数据,过期时间设为1小时,标准偏差设为5%,那么过期时间会比较均匀的分布在3400~3800秒之间。如果我们的默认过期时间是7天,那么就会均匀分布在以7天为中心点的16小时内。这样就可以很好的防止了缓存的雪崩问题。
缓存正确性
我们引入缓存的初衷是为了减小DB压力,增加系统稳定性,所以我们一开始关注的是缓存系统的稳定性。当稳定性解决之后,一般我们就会面临数据正确性问题,可能会经常遇到『明明数据更新了,为啥还是显示老的呢?』这类问题。这就是我们常说的『缓存数据一致性』问题了,接下来我们仔细下分析其产生的原因及应对方法。
数据更新常见做法
首先,我们讲数据一致性的前提是我们DB的更新和缓存的删除不会当成一个原子操作来看待,因为在高并发的场景下,我们不可能引入一个分布式锁来把这两者绑定为一个原子操作,如果绑定的话就会很大程度上影响并发性能,而且增加系统复杂度,所以我们只会追求数据的最终一致性,且本文只针对非追求强一致性要求的高并发场景,金融支付等同学自行判断。
常见数据更新方式有两大类,其余基本都是这两类的变种:
先删缓存,再更新数据库
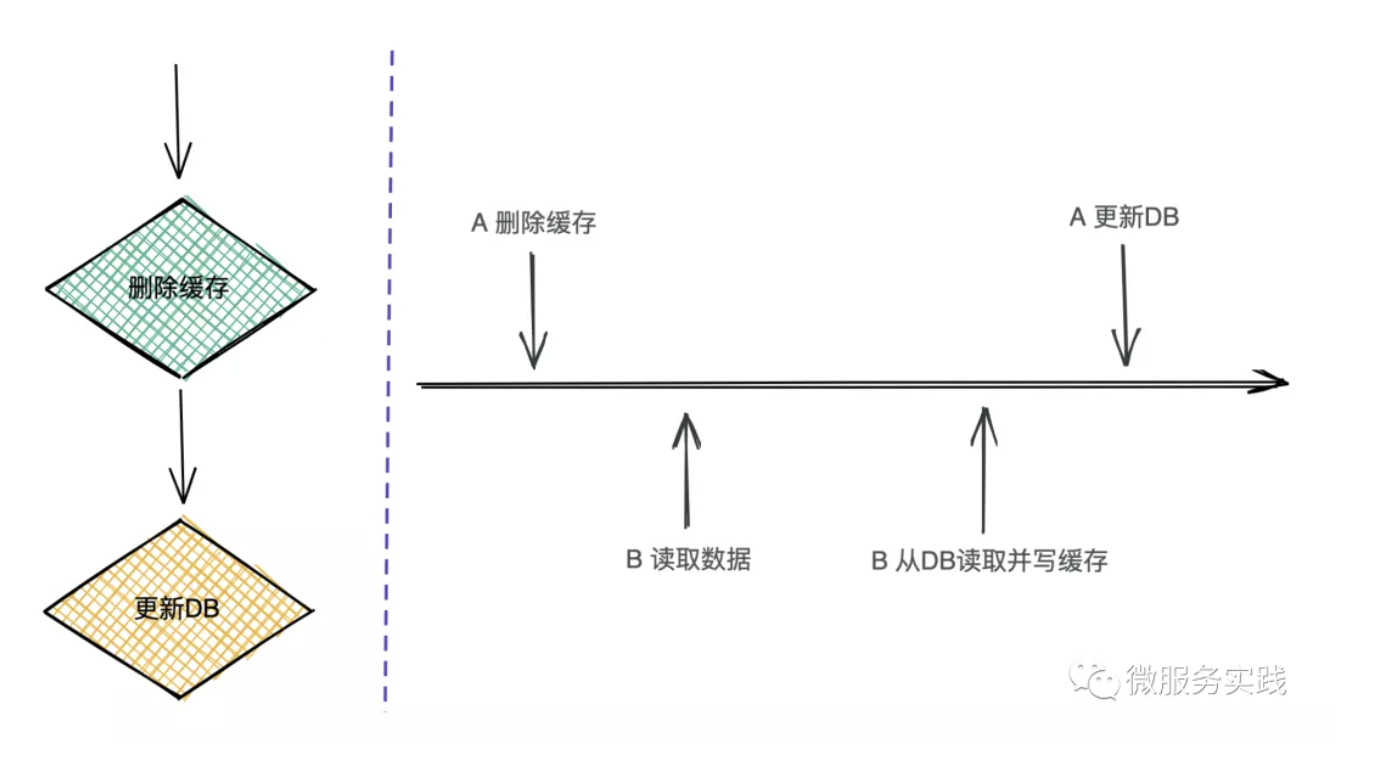
这种做法是遇到数据更新,我们先去删除缓存,然后再去更新DB,如左图。让我们来看一下整个操作的流程:
- A请求需要更新数据,先删除对应的缓存,还未更新DB
- B请求来读取数据
- B请求看到缓存里没有,就去读取DB并将旧数据写入缓存(脏数据)
- A请求更新DB
可以看到B请求将脏数据写入了缓存,如果这是一个读多写少的数据,可能脏数据会存在比较长的时间(要么有后续更新,要么等待缓存过期),这是业务上不能接受的。
先更新数据库,再删除缓存
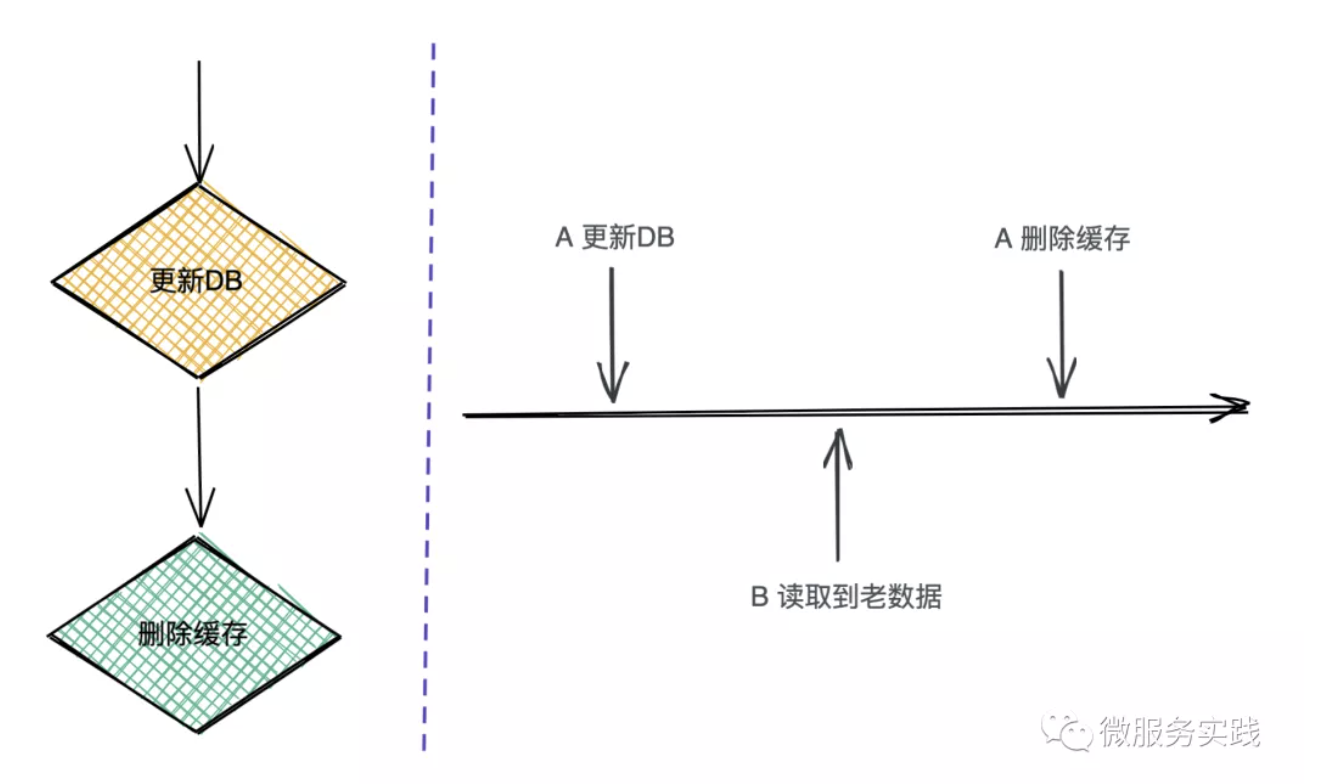
上图的右侧部分可以看到在A更新DB和删除缓存之间B请求会读取到老数据,因为此时A操作还没有完成,并且这种读到老数据的时间是非常短的,可以满足数据最终一致性要求。
上图可以看到我们用的是删除缓存,而不是更新缓存,原因如下图:
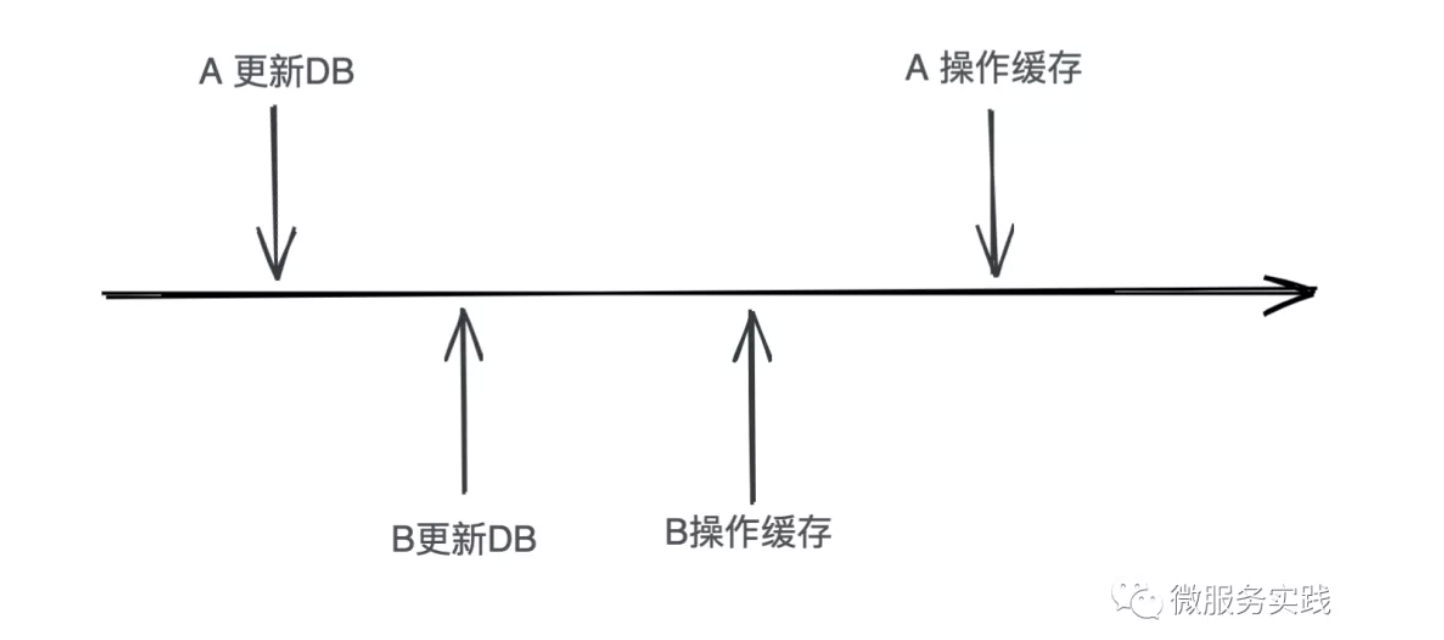
上图我用操作代替了删除或更新,当我们做删除操作时,A先删还是B先删没有关系,因为后续读取请求都会从DB加载出最新数据;但是当我们对缓存做的是更新操作时,就会对A先更新缓存还是B先更新缓存敏感了,如果A后更新,那么缓存里就又存在脏数据了,所以 go-zero 只使用删除缓存的方式。
我们来一起看看完整的请求处理流程:
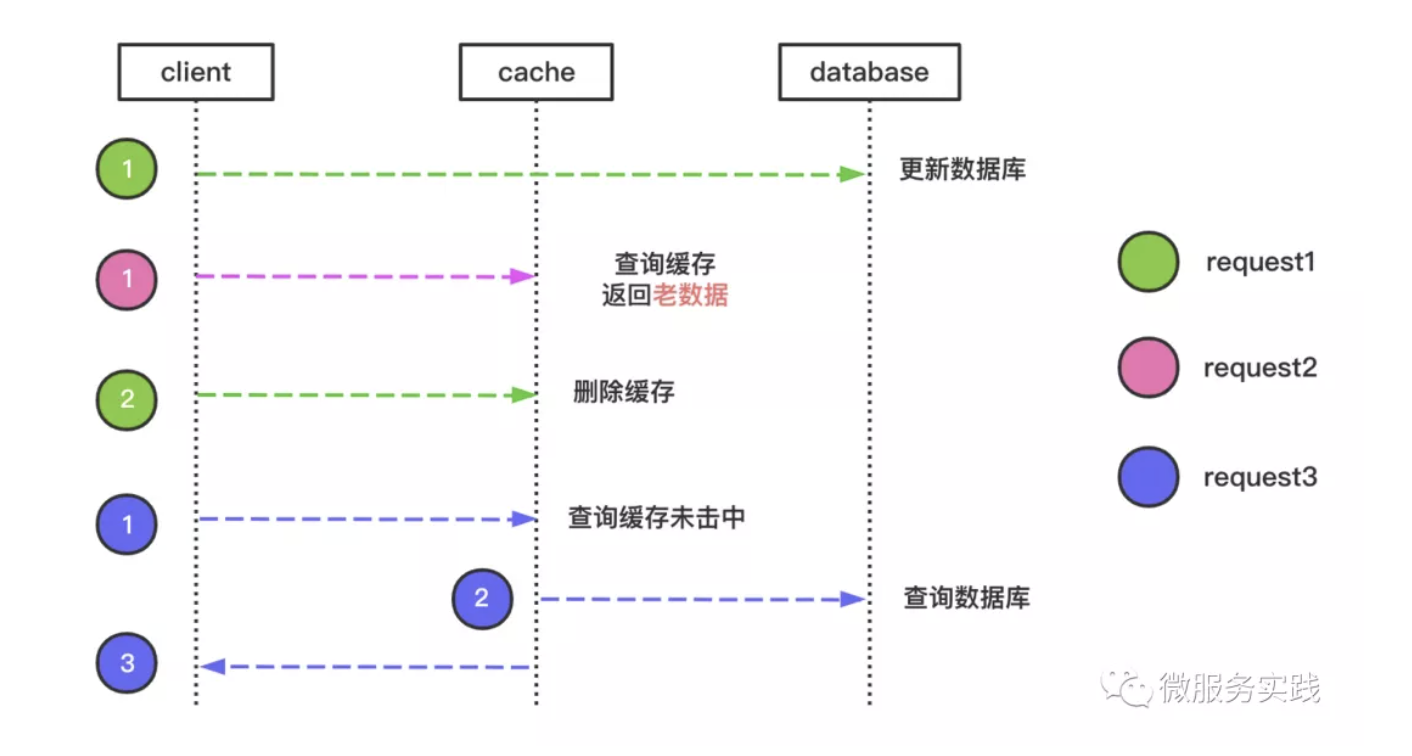
注意:不同颜色代表不同请求。
- 请求1更新DB
- 请求2查询同一个数据,返回了老的数据,这个短时间内返回旧数据是可以接受的,满足最终一致性
- 请求1删除缓存
- 请求3再来请求时缓存里没有,就会查询数据库,并回写缓存再返回结果
- 后续的请求就会直接读取缓存了
对于下图的场景,我们该怎么应对?
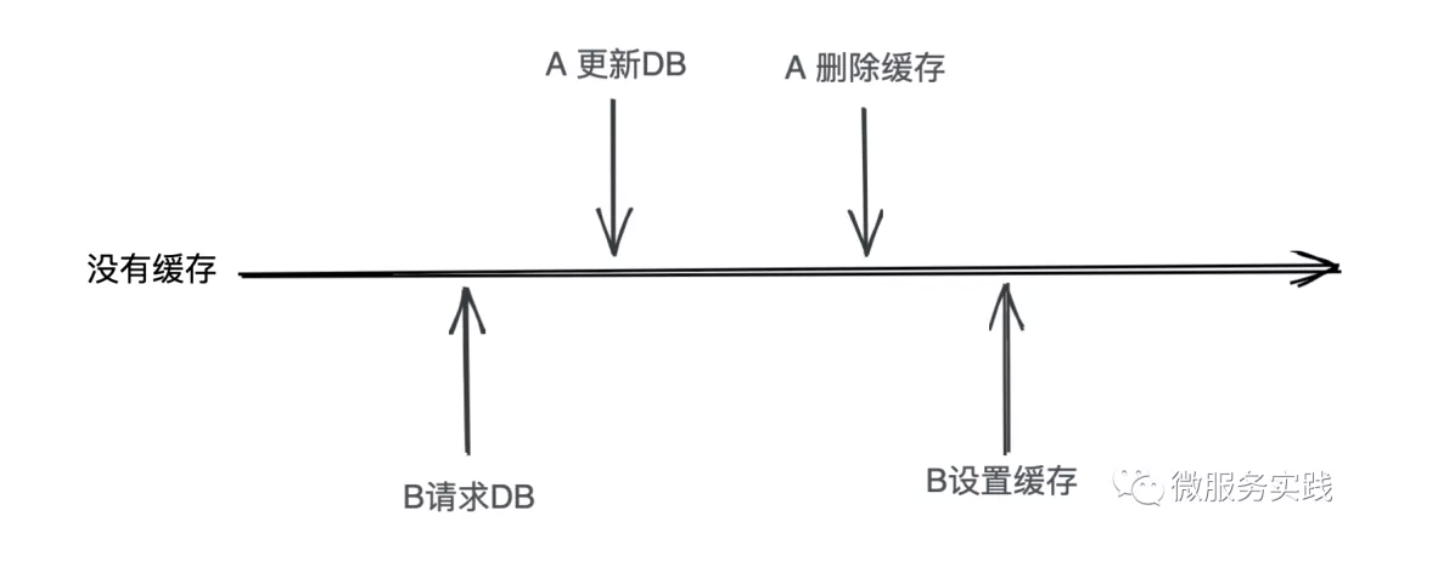
让我们来一起分析一下这个问题的几种可能解法:
利用分布式锁让每次的更新变成一个原子操作。这种方法最不可取,就相当于自废武功,放弃了高并发能力,去追求强一致性,别忘了我之前文章强调过『这个系列文章只针对非追求强一致性要求的高并发场景,金融支付等同学自行判断』,所以这种解法我们首先放弃。
把 A删除缓存 加上延迟,比如过1秒再执行此操作。这样的坏处是为了解决这种概率极低的情况,而让所有的更新在1秒内都只能获取旧数据。这种方法也不是很理想,我们也不希望使用。
把 A删除缓存 这里改成设置一个特殊占位符,并让 B设置缓存 用 redis 的 setnx 指令,然后后续请求遇到这个特殊占位符时重新请求缓存。这个方法相当于在删除缓存时加了一种新的状态,我们来看下图的情况
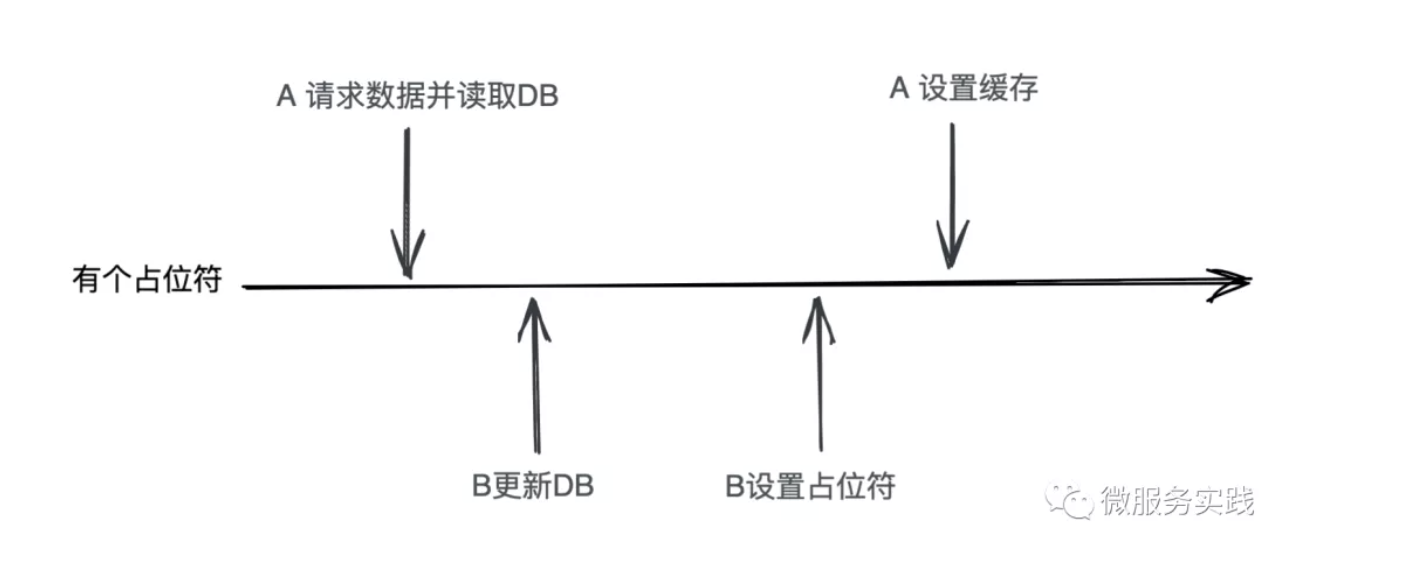
是不是又绕回来了,因为A请求在遇到占位符时必须强行设置缓存或者判断是不是内容为占位符。所以这也解决不了问题。
那我们看看 go-zero 是怎么应对这种情况的,我们选择对这种情况不做处理,是不是很吃惊?那么我们回到原点来分析这种情况是怎么发生的:
- 对读请求的数据没有缓存(压根没加载到缓存或者缓存已失效),触发了DB读取
- 此时来了一个对该数据的更新操作
- 需要满足这样的顺序:B请求读DB -> A请求写DB -> A请求删除缓存 -> B请求设置缓存
我们都知道DB的写操作需要锁行记录,是个慢操作,而读操作不需要,所以此类情况相对发生的概率比较低。而且我们有设置过期时间,现实场景遇到此类情况概率极低,要真正解决这类问题,我们就需要通过 2PC 或是 Paxos 协议保证一致性,我想这都不是大家想用的方法,太复杂了!
做架构最难的我认为是懂得取舍(trade-off),寻找最佳收益的平衡点是非常考验综合能力的。
缓存可观测性
前面两篇文章我们解决了缓存的稳定性和数据一致性问题,此时我们的系统已经充分享受到了缓存带来的价值,解决了从零到一的问题,那么我们接下来要考虑的是如何进一步降低使用成本,判断哪些缓存带来了实际的业务价值,哪些可以去掉,从而降低服务器成本,哪些缓存我需要增加服务器资源,各个缓存的 qps 是多少,命中率多少,有没有需要进一步调优等。
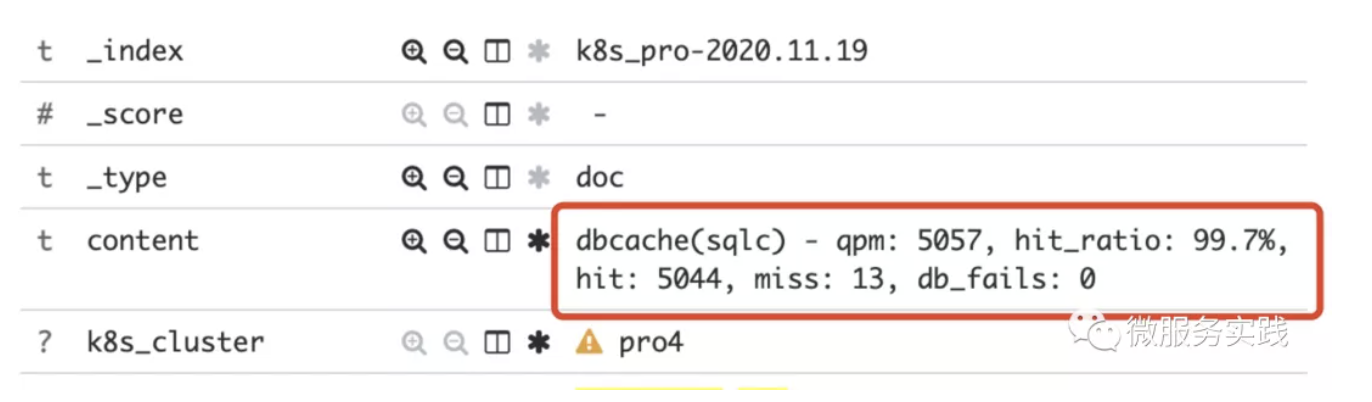
上图是一个服务的缓存监控日志,可以看出这个缓存服务的每分钟有5057个请求,其中99.7%的请求都命中了缓存,只有13个落到DB了,DB都成功返回了。从这个监控可以看到这个缓存服务把DB压力降低了三个数量级(90%命中是一个数量级,99%命中是两个数量级,99.7%差不多三个数量级了),可以看出这个缓存的收益是相当可以的。
但如果反过来,缓存命中率只有0.3%的话就没什么收益了,那么我们就应该把这个缓存去掉,一是可以降低系统复杂度(如非必要,勿增实体嘛),二是可以降低服务器成本。
如果这个服务的 qps 特别高(足以对DB造成较大压力),那么如果缓存命中率只有50%,就是说我们降低了一半的压力,我们应该根据业务情况考虑增加过期时间来增加缓存命中率。
如果这个服务的 qps 特别高(足以对缓存造成较大压力),缓存命中率也很高,那么我们可以考虑增加缓存能够承载的 qps 或者加上进程内缓存来降低缓存的压力。
所有这些都是基于缓存监控的,只有可观测了,我们才能做进一步有针对性的调优和简化,我也一直强调『没有度量,就没有优化』。
如何让缓存被规范使用?
了解 go-zero 设计思路或者看过我的分享视频的同学可能对我经常讲的『工具大于约定和文档』有印象。
对于缓存来说,知识点是非常繁多的,每个人写出的缓存代码一定会风格迥异,而且所有知识点都写对是非常难的,就像我这种写了那么多年程序的老鸟来说,一次让我把所有知识点都写对,依然是非常困难的。那么 go-zero 是怎么解决这个问题的呢?
- 尽可能把抽象出来的通用解决方法封装到框架里。这样整个缓存的控制流程就不需要大家来操心了,只要你调用正确的方法,就没有出错的可能性。
- 把从建表 sql 到 CRUD + Cache 的代码都通过工具一键生成。避免了大家去根据表结构写一堆结构和控制逻辑。

这是从 go-zero 的官方示例 bookstore 里截的一个 CRUD + Cache 的生成说明。我们可以通过指定的建表 sql 文件或者 datasource 来提供给 goctl 所需的 schema,然后 goctl 的 model 子命令可以一键生成所需的 CRUD + Cache 代码。
这样就确保了所有人写的缓存代码都是一样的,工具生成能不一样吗?