熔断
在微服务中服务间依赖非常常见,比如评论服务依赖审核服务而审核服务又依赖反垃圾服务,当评论服务调用审核服务时,审核服务又调用反垃圾服务,而这时反垃圾服务超时了,由于审核服务依赖反垃圾服务,反垃圾服务超时导致审核服务逻辑一直等待,而这个时候评论服务又在一直调用审核服务,审核服务就有可能因为堆积了大量请求而导致服务宕机
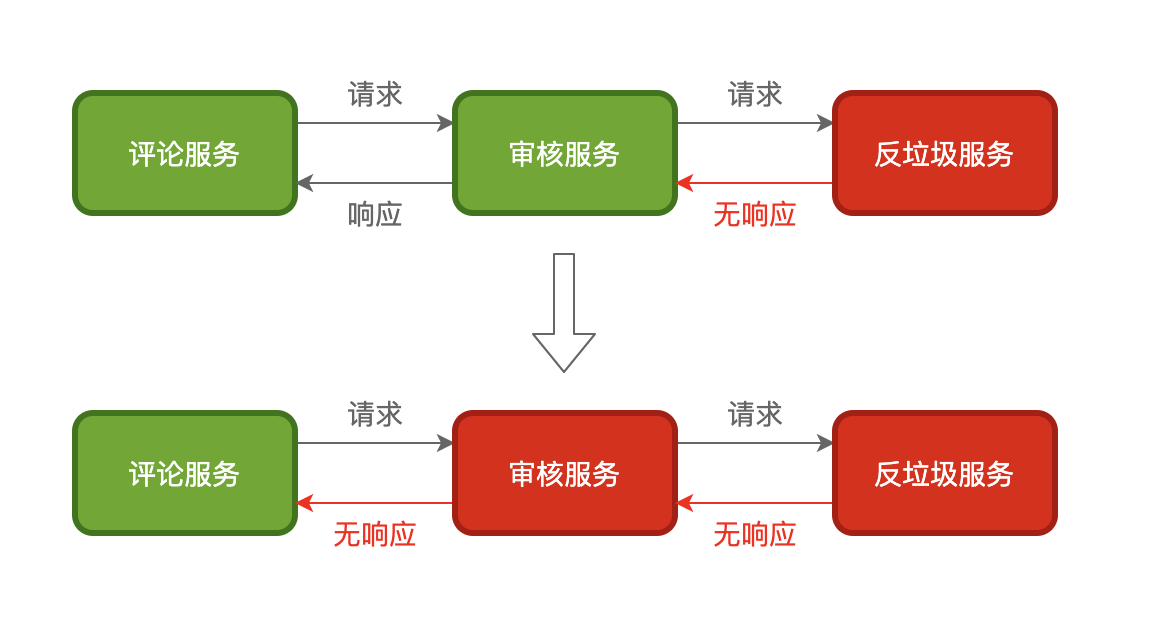
由此可见,在整个调用链中,中间的某一个环节出现异常就会引起上游调用服务出现一些列的问题,甚至导致整个调用链的服务都宕机,这是非常可怕的。因此一个服务作为调用方调用另一个服务时,为了防止被调用服务出现问题进而导致调用服务出现问题,所以调用服务需要进行自我保护,而保护的常用手段就是熔断
熔断器原理
熔断机制其实是参考了我们日常生活中的保险丝的保护机制,当电路超负荷运行时,保险丝会自动的断开,从而保证电路中的电器不受损害。而服务治理中的熔断机制,指的是在发起服务调用的时候,如果被调用方返回的错误率超过一定的阈值,那么后续的请求将不会真正发起请求,而是在调用方直接返回错误
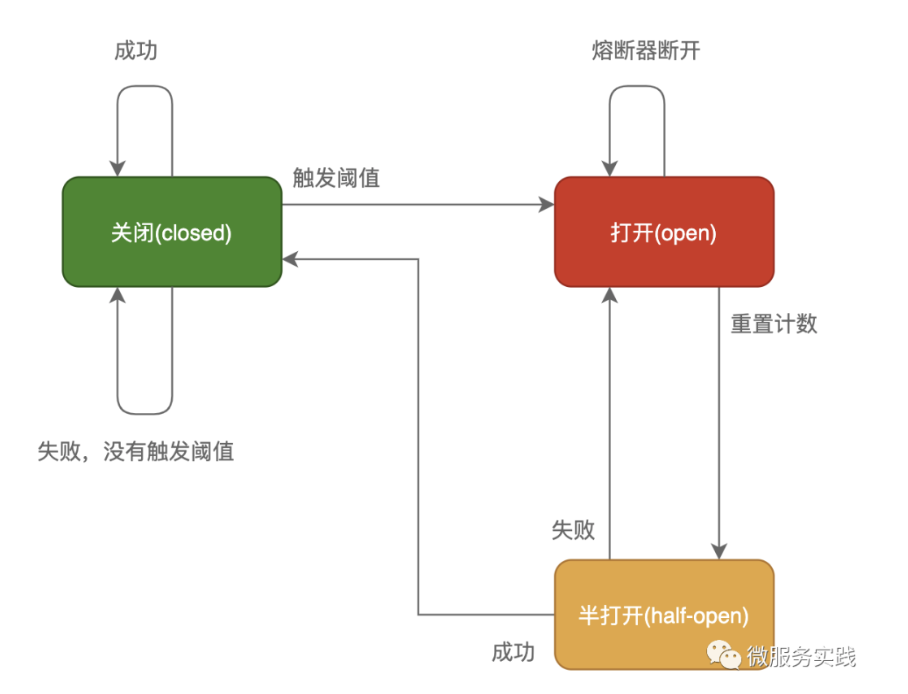
在这种模式下,服务调用方为每一个调用服务(调用路径)维护一个状态机,在这个状态机中有三个状态:
关闭(Closed):在这种状态下,我们需要一个计数器来记录调用失败的次数和总的请求次数,如果在某个时间窗口内,失败的失败率达到预设的阈值,则切换到断开状态,此时开启一个超时时间,当到达该时间则切换到半关闭状态,该超时时间是给了系统一次机会来修正导致调用失败的错误,以回到正常的工作状态。在关闭状态下,调用错误是基于时间的,在特定的时间间隔内会重置,这能够防止偶然错误导致熔断器进去断开状态
打开(Open):在该状态下,发起请求时会立即返回错误,一般会启动一个超时计时器,当计时器超时后,状态切换到半打开状态,也可以设置一个定时器,定期的探测服务是否恢复
半打开(Half-Open):在该状态下,允许应用程序一定数量的请求发往被调用服务,如果这些调用正常,那么可以认为被调用服务已经恢复正常,此时熔断器切换到关闭状态,同时需要重置计数。如果这部分仍有调用失败的情况,则认为被调用方仍然没有恢复,熔断器会切换到关闭状态,然后重置计数器,半打开状态能够有效防止正在恢复中的服务被突然大量请求再次打垮
自适应熔断器
go-zero中熔断器的实现参考了Google Sre过载保护算法,该算法的原理如下:
当服务处于过载时,有请求到达就该迅速拒绝该请求,返回一个“服务过载”类型的错误,该回复应该比真正处理该请求所消耗的资源少得多。然而,这种逻辑其实不适用于所有请求。例如,拒绝一个执行简单内存查询的请求可能跟实际执行该请求消耗内存差不多(因为这里主要的消耗是在应用层协议解析中,结果的产生部分很简单)。就算在某些情况下,拒绝请求可以节省大量资源,发送这些拒绝回复仍然会消耗一定数量的资源。如果拒绝回复的数量也很多,这些资源消耗可能也十分可观。在这种情况下,有可能该服务在忙着不停地发送拒绝回复时一样会进入过载状态。
客户端侧的节流机制可以解决这个问题。当某个客户端检测到最近的请求错误中的一大部分都是由于“服务过载”错误导致时,该客户端开始自行限制请求速度,限制它自己生成请求的数量。超过这个请求数量限制的请求直接在本地回复失败,而不会真正发到网络层。
我们使用一种称为自适应节流的技术来实现客户端节流。具体地说,每个客户端记录过去两分钟内的以下信息:
请求数量(requests)应用层代码发出的所有请求的数量总计,指运行于自适应节流系统之上的应用代码。
请求接受数量(accepts)后端任务接受的请求数量。
在常规情况下,这两个值是相等的。随着后端任务开始拒绝请求,请求接受数量开始比请求数量小了。客户端可以继续发送请求直到requests=K * accepts,一旦超过这个限制,客户端开始自行节流,新的请求会在本地直接以一定概率被拒绝(在客户端内部),概率使用如下公进行计算:

当客户端开始自己拒绝请求时,requests会持续上升,而继续超过accepts。这里虽然看起来有点反直觉,因为本地拒绝的请求实际没有到达后端,但这恰恰是这个算法的重点。随着客户端发送请求的速度加快(相对后端接受请求的速度来说),我们希望提高本地丢弃请求的概率。
我们发现自适应节流算法在实际中效果良好,可以整体上保持一个非常稳定的请求速率。即使在超大型的过载情况下,后端服务基本上可以保持50%的处理率。这个方式的一大优势是客户端完全依靠本地信息来做出决定,同时实现算法相对简单:不增加额外的依赖,也不会影响延迟。
对那些处理请求消耗的资源和拒绝请求的资源相差无几的系统来说,允许用50%的资源来发送拒绝请求可能是不合理的。在这种情况下,解决方案很简单:通过修改客户端中算法的accepts的倍值K(例如,2)就可解决:
降低该倍值会使自适应节流算法更加激进。
增加该倍值会使该算法变得不再那么激进。
举例来说,假设将客户端请求的上限从request=2 accepts调整为request=1.1 accepts,那么就意味着每10个后端请求之中只有1个会被拒绝。一般来说推荐采用K=2,通过允许后端接收到比期望值更多的请求,浪费了一定数量的后端资源,但是却加快了后端状态到客户端的传递速度。举例来说,后端停止拒绝该客户端的请求之后,所有客户端检测到这个变化的耗时就会减小。
type googleBreaker struct {
k float64 // 倍值 默认1.5
stat *collection.RollingWindow // 滑动时间窗口,用来对请求失败和成功计数
proba *mathx.Proba // 动态概率
}
自适应熔断算法实现:
func (b *googleBreaker) accept() error {
accepts, total := b.history() // 请求接受数量和请求总量
weightedAccepts := b.k * float64(accepts)
// 计算丢弃请求概率
dropRatio := math.Max(0, (float64(total-protection)-weightedAccepts)/float64(total+1))
if dropRatio <= 0 {
return nil
}
// 动态判断是否触发熔断
if b.proba.TrueOnProba(dropRatio) {
return ErrServiceUnavailable
}
return nil
}
每次发起请求会调用doReq方法,在这个方法中首先通过accept校验是否触发熔断,acceptable用来判断哪些error会计入失败计数,定义如下:
func Acceptable(err error) bool {
switch status.Code(err) {
case codes.DeadlineExceeded, codes.Internal, codes.Unavailable, codes.DataLoss: // 异常请求错误
return false
default:
return true
}
}
如果请求正常则通过markSuccess把请求数量和请求接受数量都加一,如果请求不正常则只有请求数量会加一
func (b *googleBreaker) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error {
// 判断是否触发熔断
if err := b.accept(); err != nil {
if fallback != nil {
return fallback(err)
} else {
return err
}
}
defer func() {
if e := recover(); e != nil {
b.markFailure()
panic(e)
}
}()
// 执行真正的调用
err := req()
// 正常请求计数
if acceptable(err) {
b.markSuccess()
} else {
// 异常请求计数
b.markFailure()
}
return err
}
使用示例
go-zero框架中默认开启熔断保护,不需要额外再配置
在非go-zero项目中如想实现熔断,也可单独移植过去使用
当触发熔断会报如下错误:
var ErrServiceUnavailable = errors.New("circuit breaker is open")
总结
调用端可以通过熔断机制进行自我保护,防止调用下游服务出现异常,或者耗时过长影响调用端的业务逻辑,很多功能完整的微服务框架都会内置熔断器。其实,不仅微服务调用之间需要熔断器,在调用依赖资源的时候,比如mysql、redis等也可以引入熔断器的机制。